python||判断K-Means聚类最佳数量
在进行K均值聚类之前,不知道聚成几类效果是最好的,经过查资料,发现有两种常用的方式。分别是:
1.肘方法
2.轮廓系数法
这篇文章记录使用肘方法判断聚类最佳数量,肘方法的原理是什么呢?

这是来自一个博友的解释,我一个没学过理科的人也看不懂。接下来直接开始操作:
这是我的原始数据:

看一下python代码实现:
import pandas as pd #导入pandas库
import numpy as np
from sklearn.cluster import KMeans #导入k均值函数
import matplotlib.pyplot as plt
import xlrd
file_path=xlrd.open_workbook("cluster_MinMax.xls") #读取文件
table = file_path.sheets()[0] #读取文件,获取第一个sheet页,赋值给table
my_data=[] #创建一个空列表
for i in range(table.nrows): #nrows为表的行数,遍历nrows的行数
if i == 0: #忽略第一行
continue
else:
my_data.append(table.row_values(i)[0:]) #把第i行的数据添加到data列表里去
featureList = ['0', '1', '2','3','4','5','6','7'] #创建了一个特征列表,这是我原始表格里的特征名
mdl = pd.DataFrame.from_records(my_data, columns=featureList)
#把my_data里的数据放进来,列的名称=featurelist
# '利用SSE选择k'
SSE = [] # 存放每次结果的误差平方和
for i in range(1, 8): #尝试要聚成的类数
estimator = KMeans(n_clusters=i) # 构造聚类器
estimator.fit(np.array(mdl[['0', '1', '2','3','4','5','6','7']]))
SSE.append(estimator.inertia_)
X = range(1, 8) #跟k值要一样
plt.xlabel('i')
plt.ylabel('SSE')
plt.plot(X, SSE, 'o-')
plt.show() #画出图
运行之后,出现了这个图:
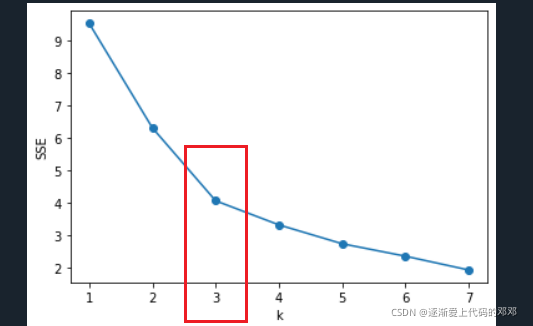
拐肘最明显的数字就代表了聚类的最佳数量,对于我这个数据集来说,最佳聚类数量是3类。
但是在实现这个肘方法的过程中我遇到了不少问题,也一并记录下来:
一.xlsx文件无法读取的问题

报错:

出现这个问题的原因是xlrd1.2.0之后的版本不支持xlsx格式的excel文件,有两种方式可以解决:
1.改xlrd版本,改到1.2.0版本
在anaconda prompt里卸载当前xlrd,安装xlrd1.2.0:
pip uninstall xlrd
pip install xlrd==1.2.0
2.改excel文件格式
把xlsx改到xls即可,改完之后就可以读取了
![]()
做的过程中参考了这篇博文: