azkaban的安装、配置与使用详解
1、下载安装包并编译
1.下载如下软件安装包,上传至虚拟机并解压
gradle-5.6.3-all.zip
azkaban-3.84.10.tar.gz tmp

[root@hadoop100 software]# tar -zxvf azkaban-3.84.10.tar.gz
[root@hadoop100 software]# unzip gradle-5.6.3-all.zip
2.进入azkaban源码的解压包,进行编译
[root@hadoop100 azkaban-3.84.10]# cd /opt/software/azkaban-3.84.10
[root@hadoop100 azkaban-3.84.10]# ./gradlew build installDist -x test
编译成功后在下面三个文件夹中找到如下的三个压缩包

./azkaban-db/build/distributions/azkaban-db-0.1.0-SNAPSHOT.tar.gz
./azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
./azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz
创建目录/opt/software/azkaban,将三个压缩包拷贝到里面并解压
[root@hadoop100 software]# mkdir azkaban
[root@hadoop100 software]# cd azkaban/
[root@hadoop100 azkaban]# tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
[root@hadoop100 azkaban]# tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz
[root@hadoop100 azkaban]# tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz
[root@hadoop100 azkaban]# mv azkaban-exec-server-0.1.0-SNAPSHOT azkaban-exec
[root@hadoop100 azkaban]# mv azkaban-web-server-0.1.0-SNAPSHOT azkaban-web
[root@hadoop100 azkaban]# rm -f *.gz
2、MySQL创建azkaban数据库和用户
- 修改MySQL的内存
vi /etc/my.cnf
//在最后一行加入如下的内容,进行修改
max_allowed_packed=1024M
- 新建azkaban数据库
mysql> create database azkabandb;
- 创建azkaban用户
mysql> create user 'azkaban'@'%' identified by '123456';
- 给azkaban用户赋权
mysql> grant select,insert,update,delete,on azkabandb.* to 'azkaban'@'%' with grant option;
- 创建azkaban存储在mysql中的元数据表格
解压1.2中得到的压缩包:azkaban-db-0.1.0-SNAPSHOT.tar.gz
找到创建元数据表格的脚本:create-all-sql-0.1.0-SNAPSHOT.sql
在mysql的azkaban库中,执行脚本,进行建表:
mysql> source /opt/software/azkaban/azkaban-db-0.1.0-SNAPSHOT/create-all-sql-0.1.0-SNAPSHOT.sql
3、配置azkaban-exec
- 进入如下的配置文件
cd /opt/software/azkban/azkaban-exec/conf
vi azkaban.properties
- 修改时区,将默认地址改为亚洲上海

- 修改网页服务url的IP地址为本机IP地址

- 修改azkaban数据库信息(地址为MySQL数据库所在的机器的IP地址,其他是在上面2.3新建的azkaban的用户信息)
- 增加端口号12321为指定登录端口
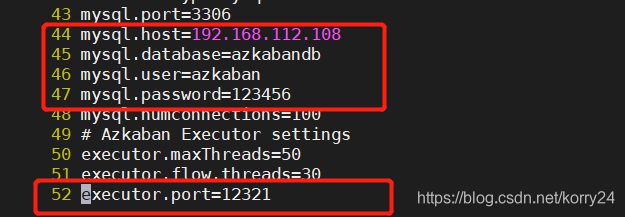
- 启动azkaban-exec
[root@hadoop100 azkaban-exec]# bin/start-exec.sh
[root@hadoop100 azkaban-exec]# jps
2594 AzkabanExecutorServer
2605 Jps
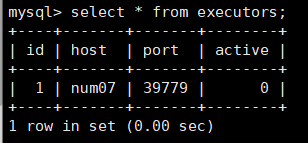
- 登录MySQL,查看azkabandb数据库下的executors,此时的用户是未激活状态,如下图active状态为0
- 激活用户
[root@hadoop100 azkaban-exec]# curl -G "192.168.112.100:12321/executor?action=activate" && echo
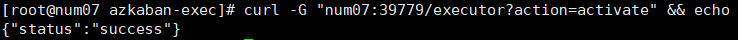
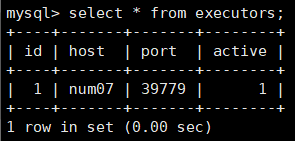
- 再次查看executors,active状态为1,表示激活 ,azkaban-exec配置完成
4、配置azkaban-web
1.编辑配置文件 azkaban.properties
[root@hadoop100 conf]# cd /opt/software/azkban/azkaban-web/conf
[root@hadoop100 conf]# vi azkaban.propertie
//时区改为亚洲上海
7 default.timezone.id=Asia/Shanghai
//修改azkaban数据库信息
41 mysql.host=192.168.112.108
42 mysql.database=azkabandb
43 mysql.user=azkaban
44 mysql.password=123456
//MinimumFreeMemory限制可用内存需要在6G以上,当不满足条件时将不开启web,这里为了演示将该项删除
48 azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus

2. 修改azkaban-user.xml
[root@hadoop100 conf]# vi ./azkaban-users.xml
添加一个用户,登录web时使用。设置用户名和密码,注意将用户角色设为admin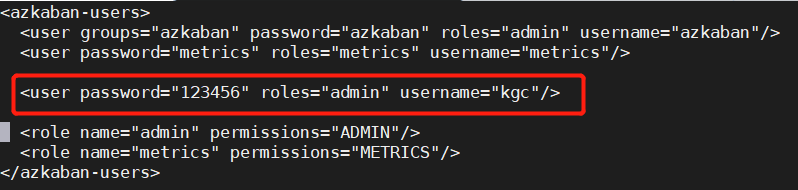
3. 启动azkaban-web
[root@hadoop100 azkaban-web]# cd /opt/software/azkban/azkaban-web
[root@hadoop100 azkaban-web]# ./bin/start-web.sh
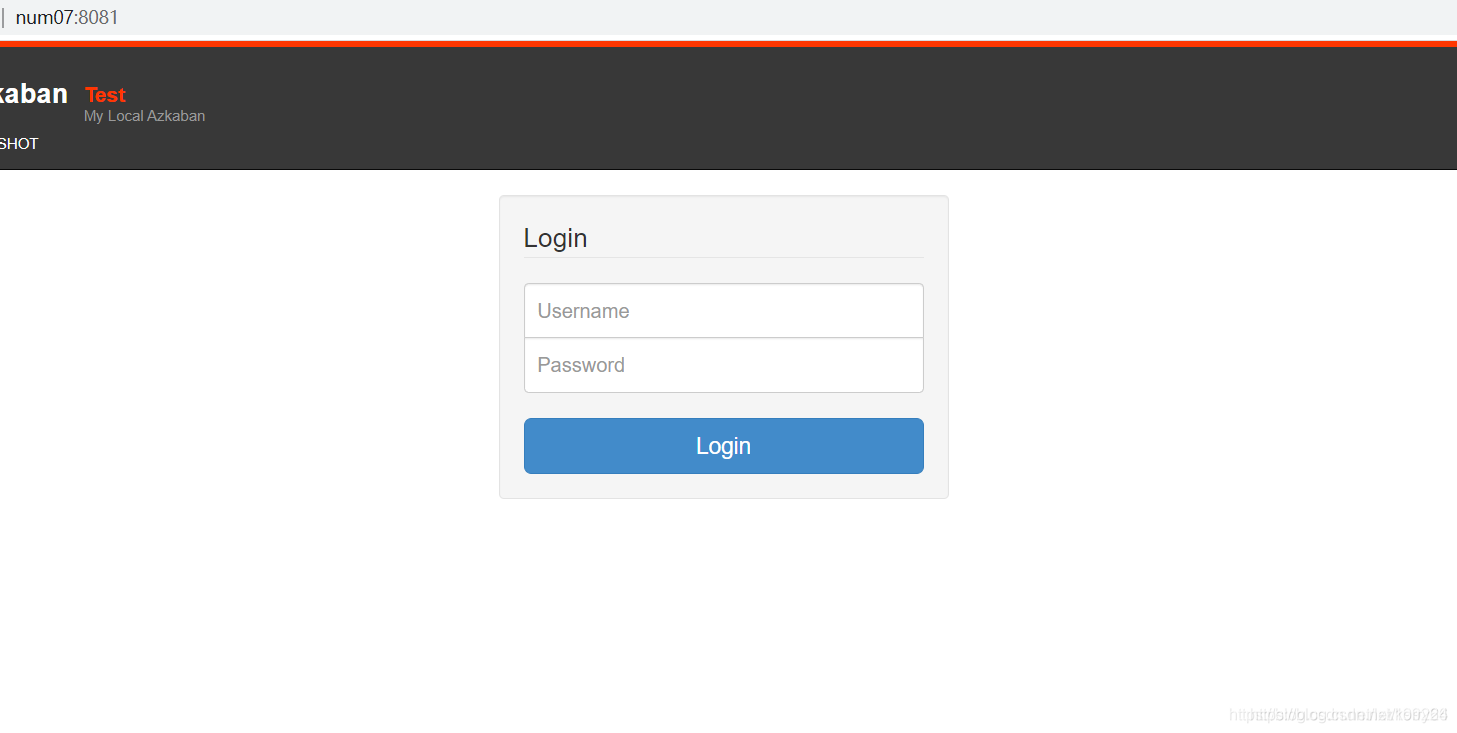
4.测试
- 在网页输入我们的IP地址和上面设置的8081端口,输入刚才添加的用户和密码
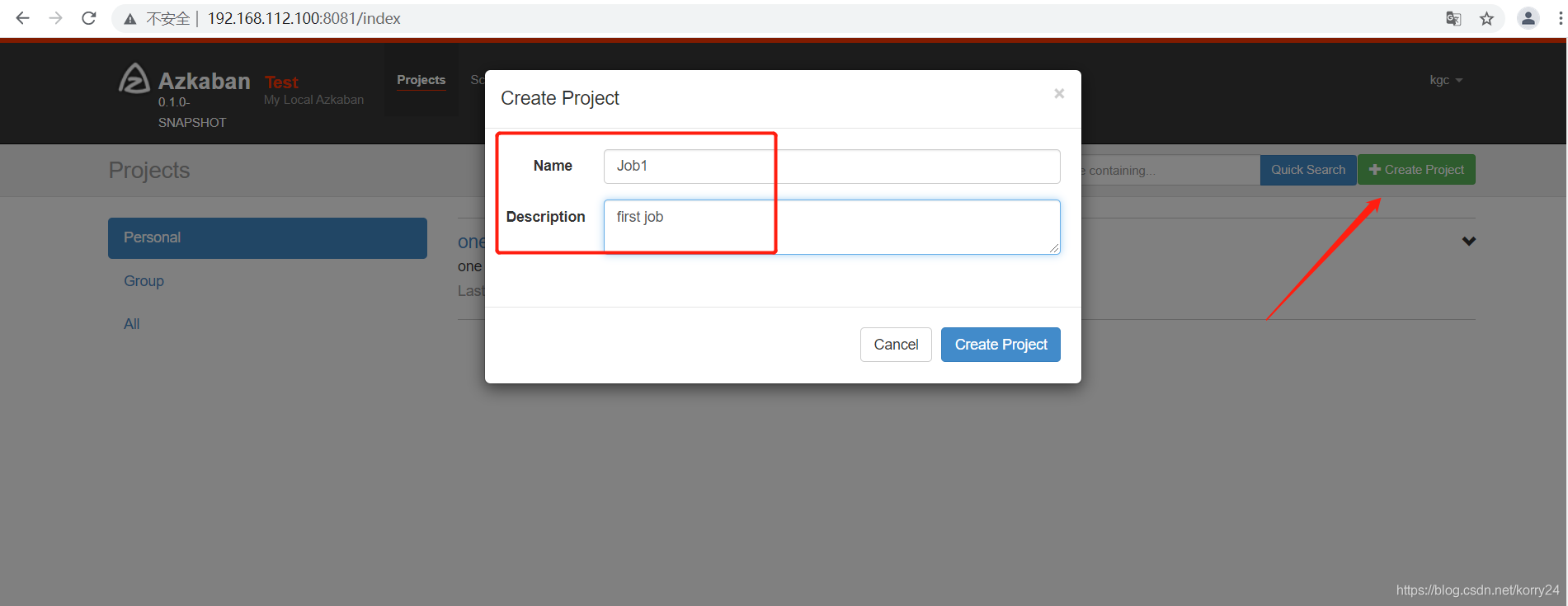
- 创建项目
- ①创建文件azkaban.project:
编辑内容:azkaban-flow-version: 2.0
②创建任务文件:One.flow
编辑内容:
//文件要用notepad++修改为Unix格式,编写语言为YAML,只能用空格
//将两个文件打成.zip压缩包,作为要上传的文件
nodes:
- name: firstJob
type: command
config:
command: echo "hello world"
- 上传文件,即可执行任务
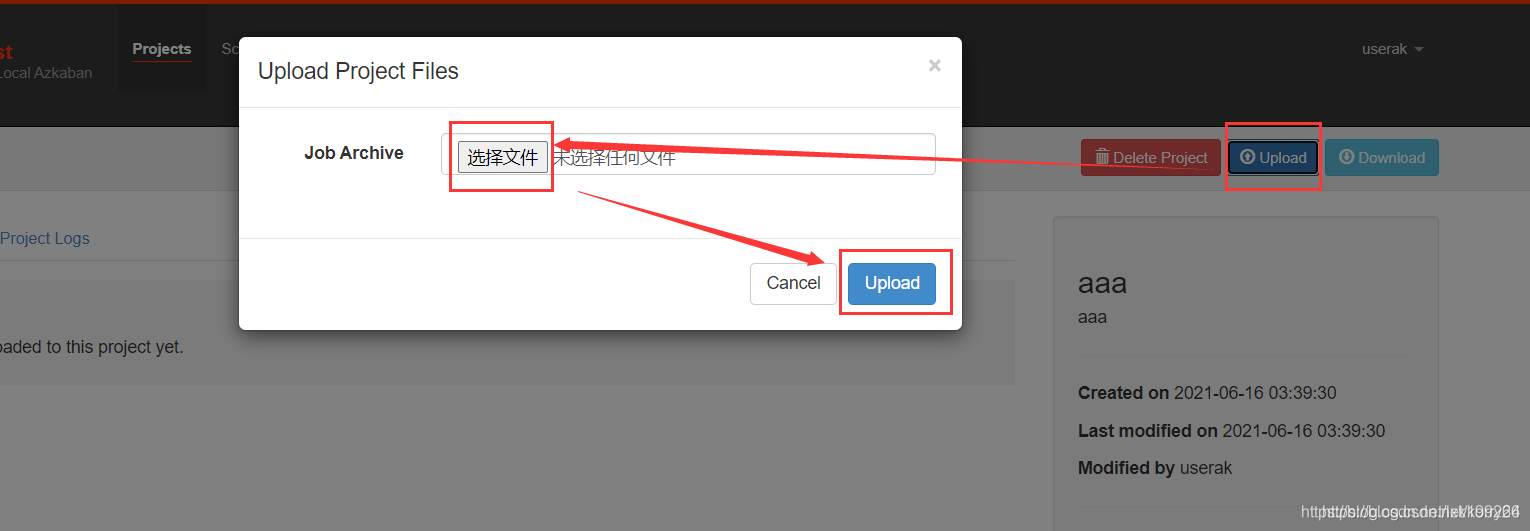
- 点击Excete Flow执行任务
5、案例演示
- condition和脚本的使用
//①创建任务文件
nodes:
- name: jobA
type: command
config:
command: sh jobA.sh
- name: jobB
type: command
dependsOn:
- jobA
config:
command: sh jobB.sh
condition: ${jobA:wk} == 1 #符合此条件,则执行jobB
//②创建脚本jobA.sh
#!/bin/base
echo "do jobA.sh"
wk= 'date +%w'
echo "{\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE
//③创建脚本jobB.sh
#!/bin/bash
echo "do jobB"
//④创建项目问价
azkaban-flow-version: 2.0
- dependsOn和one_success的使用
depends表示依赖于后面所列出来的job的结果
one_success表示,只要有一个成功即执行后面的任务
nodes:
-name: jobA
type: command
config:
conmand: sh jobA.sh
-name: jobB
type: command
config:
conmand: sh jobB.sh
-name: jobC
type: command
dependsOn:
- jobA
- jobB
config:
conmand: sh jobC.sh
condition: one_success
- 操作Hbase数据库
//创建hbase.sh脚本
list_namespace
exit
//创建任务文件
nodes:
- name: jobhbase
type: command
config:
command: hbase shell hbase.sh
- 操作hive数据库
//创建myhive.sql脚本
create database if not exists exam202106;
user exam202106;
drop table if exists azinfo;
create table azinfo(id int,name string)
row format delimited fields terminated by ',';
load data inpath '/opt/azkaban/info.txt' into table azinfo;
drop table if exists azres;
create table azres as select * from azinfo;
//创建任务文件
nodes:
- name: hivedemo
type: command
config:
command: hive -f myhive.sql
- 执行Java代码
//创建任务文件,Xms和Xmx分别问最小值和最大值,kgc kb11为传入的两个参数
nodes:
- name: javaJob
type: javaprocess
config:
Xms: 100M
Xmx: 200M
java.class: nj.zb.kb11.TestJavaProcess kgc kb11
- 通过API操作spark

//创建任务文件(代码全类名+代码jar包)
nodes:
- name: jobspark
type: command
config:
command: spark-submit --class nj.zb.kb11.AzkabanSparkDemo ./azkabandemo-1.0-SNAPSHOT.jar