文本分类识别系统Python+卷积神经网络算法+TensorFlow+Django网页界面
一、介绍
文本分类系统,使用Python作为主要开发语言,通过选取的中文文本数据集(“体育类”, “财经类”, “房产类”, “家居类”, “教育类”, “科技类”, “时尚类”, “时政类”, “游戏类”, “娱乐类”),基于TensorFlow搭建CNN卷积神经网络算法模型,并进行多轮迭代训练最后得到一个识别精度较高的模型文件。然后使用Django框架开发网页端可视化界面平台。实现用户输入一段文本识别其所属的种类。
二、效果图片展示
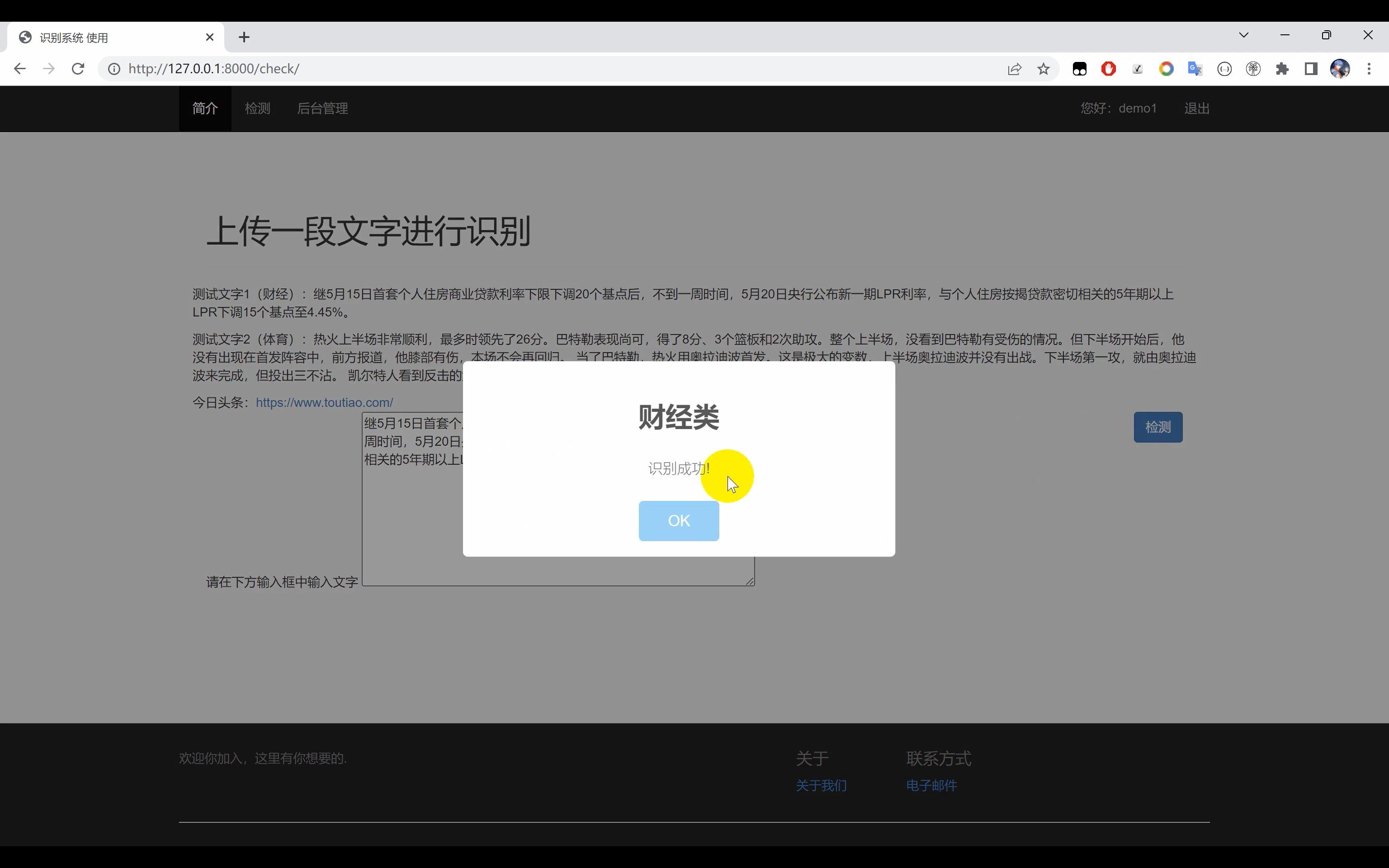
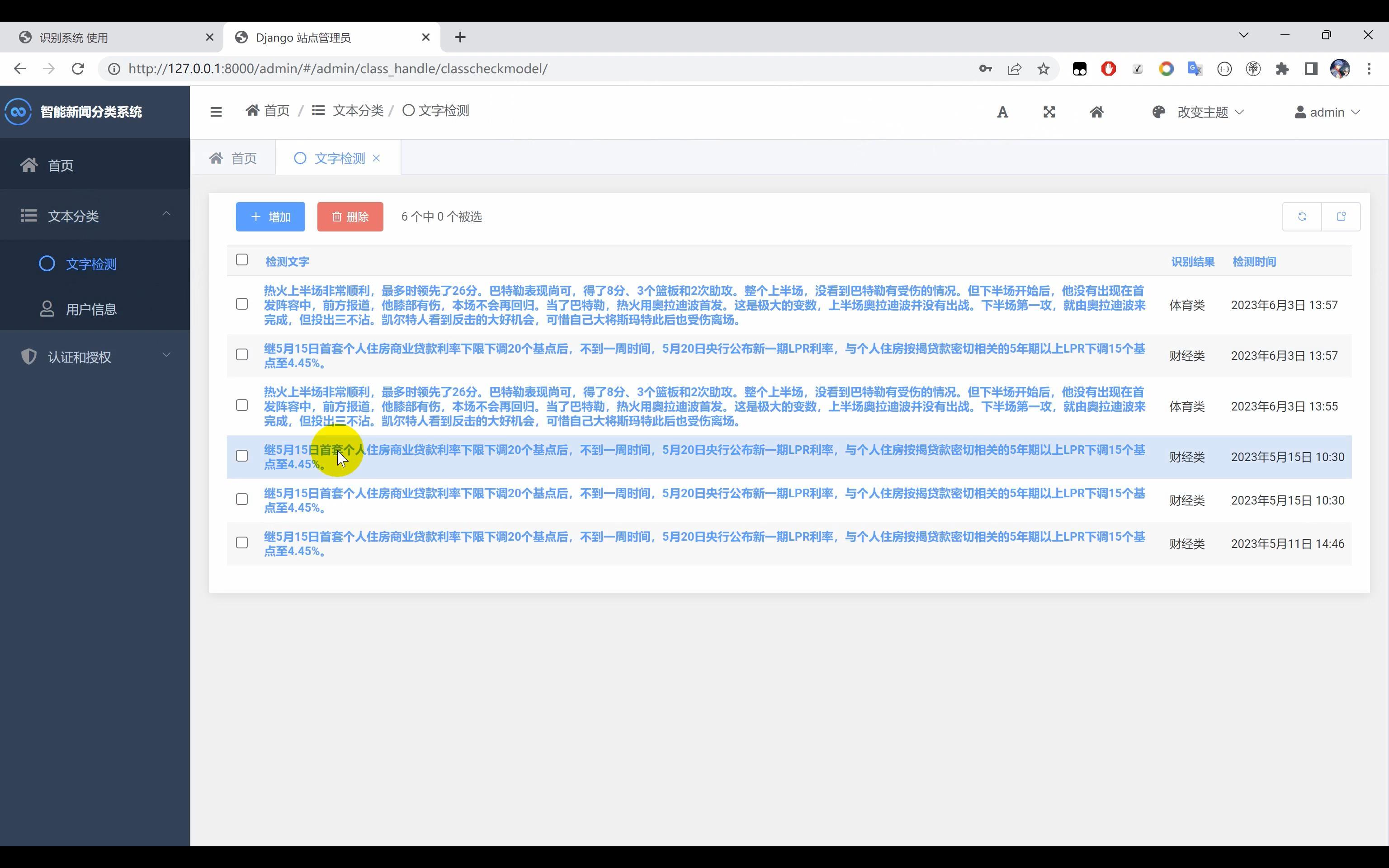
三、演示视频 and 代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/dm2c902i8cckeayy
四、卷积神经网络介绍
CNN(卷积神经网络)原本主要用于图像处理领域,但它也被成功应用于文本分类识别。在这个领域,CNN能够有效识别文本中的局部特征,例如词组或短语,并通过学习这些特征来进行文本分类。
在文本处理中,通常首先将文本转换为向量形式,比如使用词嵌入(word embeddings)如Word2Vec或GloVe。这些向量化的文本数据之后会作为CNN的输入。CNN通过其卷积层可以捕捉到文本中的局部相关性,例如词与词之间的关联。经过多个卷积和池化(pooling)层后,网络能够从文本中提取有用的特征,并通过全连接层进行分类。
下面是一个使用TensorFlow和Python的简短示例代码,展示了如何构建一个用于文本分类的简单CNN模型:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
# 假设词汇表大小为10000,嵌入维度为128,分类数量为5
vocab_size = 10000
embedding_dim = 128
num_classes = 5
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim, input_length=500))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 打印模型概览
model.summary()
这个例子中,我们首先定义了一个顺序模型(Sequential)。模型的第一层是Embedding层,用于将词汇索引映射到其嵌入向量。接下来是一个卷积层(Conv1D),用于提取文本特征。然后是一个全局最大池化层(GlobalMaxPooling1D),用于减少参数数量并防止过拟合。最后是一个全连接层(Dense),用于分类。
这段代码提供了构建文本分类CNN模型的基础框架,可以根据具体的应用场景进行调整和优化。