【深度视觉】第十一章:语义分隔
十三、语义分隔
前面讲的都是视觉识别中的图像分类任务以及图像分类的几个经典算法,下面我们开始语义分隔任务。
1、视觉识别的四大任务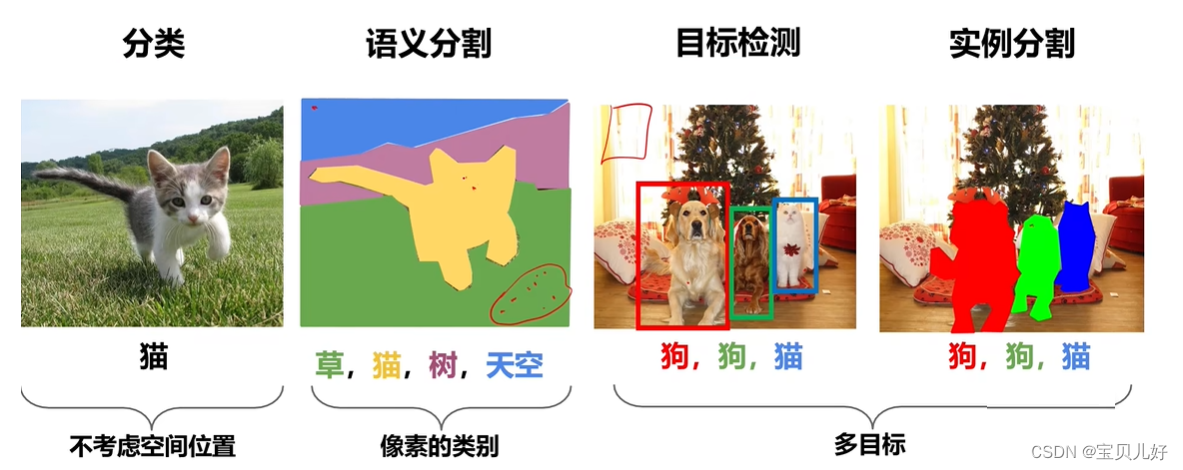
分类任务:就是用我们前面讲的经典架构和前沿网络来对图像进行分类,看图像是猫还是狗还是汽车还是青蛙的这种整图的分类任务,就是给一个整图打一个标就好了。
语义分隔:是像素级的分类任务,就是对图像中的每个像素都进行分类。就是对原图的每个像素都分是猫还是草还是树还是天空等这种分类任务。
目标检测:是在图像的区域中进行分类,就是滑窗滑动,判断滑窗图像的类别。相当于是区域级的分类问题。
实例分隔:也是像素级的分类任务,但比语义分隔更复杂。实例分隔是在语义分隔的基础上,还得分狗A狗B猫A猫B。就是不仅要区分一个像素是不是目标像素,还得区分这个像素是谁,是狗A还是猫B呀?
可见,分类、目标检测、语义分隔、实例分隔都是分类任务,只是对图片识别的程度不一样,所以它们对应的标签也是不一样的。
分类是对图像了解程度最浅的一个任务,分类模型得到的信息也是最少的,也就是标签只有"是"或"不是"这种简单的信息。
目标检测,模型得到的信息是一个区域级的信息,也就是训练数据的标签是图像某些区域的"是"或"不是"这种信息。
语义分隔,其训练数据的标签是一个像素级的标签。
实例分隔的标签就是基于实例的像素级,就是不仅要告诉你这个像素"是"或"不是",还得告诉你这个"是"的像素是谁。
也所以,目标检测模型、语义分隔模型、实例分隔模型都是基于前面我们学的googlenet、resnet或者VGG改进而来的。
2、语义分隔思想及原理
就是给每个像素分配类别标签,不区分实例,只考虑像素类别。
(1)语义分隔思路1:
只要我们指定窗口的尺寸,上图的语义分隔思想就是可行的。但是这种操作效率太低!重叠区域的特征反复被计算,就是相邻很近的像素周围的区域不断被送入CNN被重复不断地进行特征计算,这样就非常低效。为了避免重复计算,就出现了全卷积神经网络。我们知道卷积层本来就是提取特征的,全卷积网络就可以一次性把一整张图的特征都计算出来,那所以最后只要一次性输出所有像素的类别即可:
(2)语义分隔思路2:
这种思路我们就基本不怎么care输入图像的尺寸了,只要我们只要padding保证上图红框部分的尺寸和原图一直保持一致就可以了。
上图我们的标答是一个四分类:牛、天空、草地、树,所以每张图片的每个像素的标答的one-hot形式就是长度为4,也就是上图的C就得是4。
思路2虽然比思路1的计算量小了,但也有很明显的弊端就是:处理过程中一直保持原始分辨率,对显存的需求就会非常庞大。我们知道要想提取更复杂的特征和语义就得加深网络,那特征图如果一直保持很大的尺寸,深度就必然要受到算力的制约!我们知道VGG加深网络是在不断减半特征图的基础上加深网络的,就这样vgg的参数都是天量的了。我们知道在CNN网络中,所有向前传播的参数和中间结果都是要保存的,用来反向传播计算梯度的,如果前向的变量实在是太多,硬件肯定是支撑不了的。所以对于大尺寸图片思路2也是无能为力的。
(3)语义分隔思路3: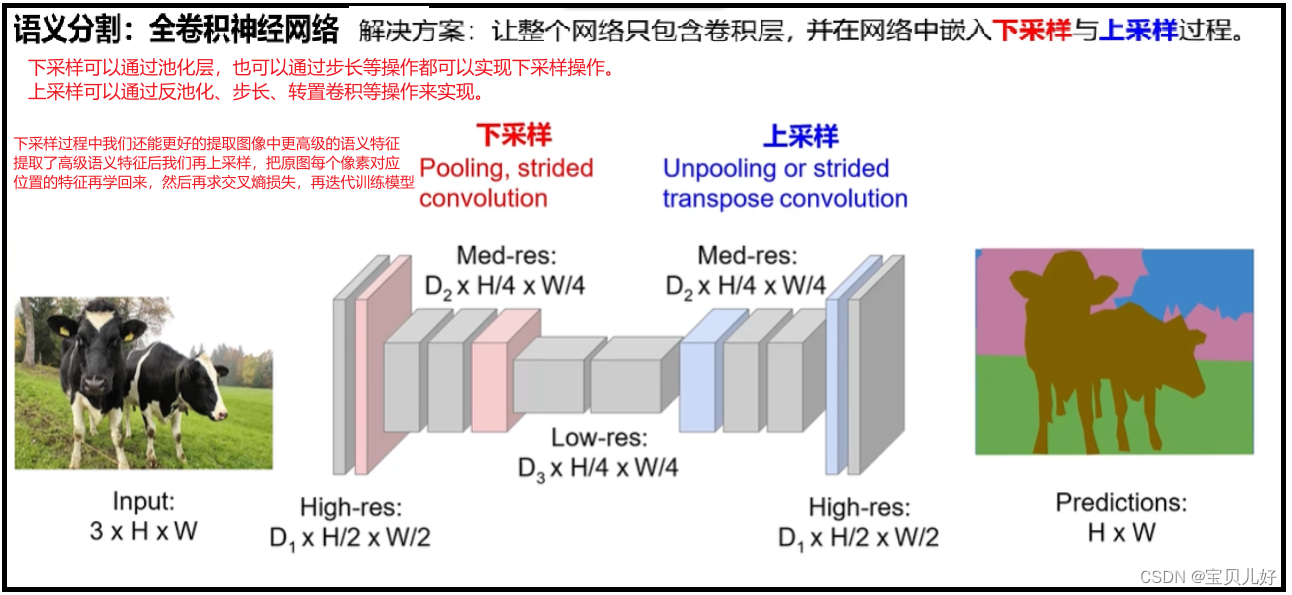
至于上下采样的具体实现方法,我们的【深度视觉】第五章:卷积网络的重要概念及花式卷积,中的转置卷积部分写的非常清楚,有相关实现的api,大家可以参考。
另外,上图中的D1是必须等于类别个数的,和上图的C的值是一样的!
3、语义分隔模型:U-Net
(1)U-Net简介
U-Net可以说是最常用、最简单的一种分割模型了,简单、高效、易懂、易构建、可以从小数据集中训练,是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型。论文连接:https://arxiv.org/abs/1505.04597 大家可以自行下载原论文阅读。
(2)U-Net和FCN、Autoencoder之间的渊源
首先,U-Net和FCN都是在Autoencoder(AE)之后提出的,也就是说U-Net和FCN都是借鉴了Autoencoder的思想框架。Autoencoder是自动编码器,也就是编码和解码(encoder-decoder),早在2006年就被Hinton大神提出来并发表在nature上了,此后,经过业界的魔改,现在已经形成自动编码器家族Autoencoders,这个家族是深度学习领域经典的无 监督网络一派,不仅用在语义分隔,在图像生成领域、图像降噪、图像压缩、风格迁移等领域也是有不可撼动的绝对地位的。下图是自动编码器的网络架构: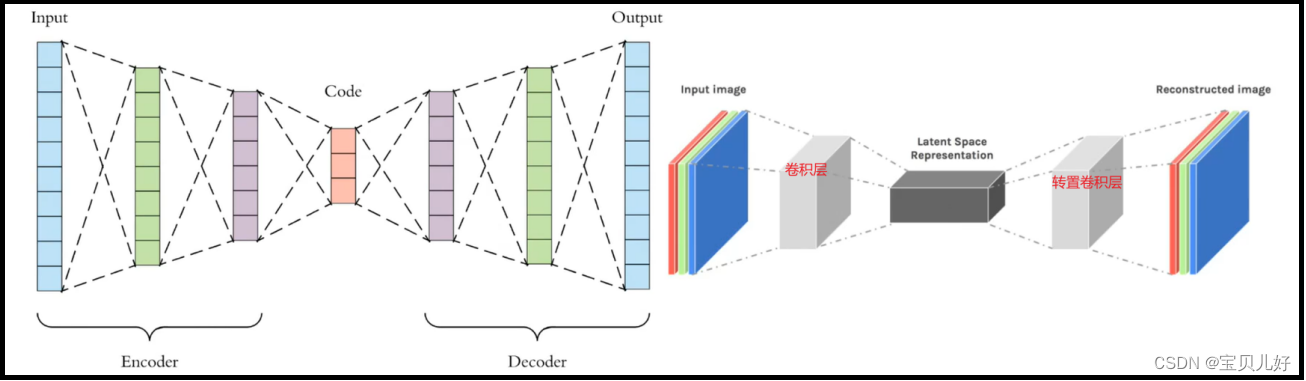
其次,U-Net比FCN(Fully Convolutional Netowkrs)稍晚提出来,但都发表在2015年。和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,也就是特征图融合环节,FCN用的是加操作(summation),就是把特征图对应位置的特征值相加来融合特征;U-Net用的是叠操作(concatenation),就是通过通道数的拼接,形成更厚的特征,当然这样会更佳消耗显存。
再次,在U-Net和FCN被提出后的几年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的拓扑结构是没有改动的。举例来说,在ICCV上何凯明大神提出的Mask RCNN,相当于一个检测,分类,分割的集大成者,我们仔细去看它的分割部分,其实使用的也就是这个简单的FCN结构。这说明了这种“U形”的编码解码结构确实非常的简洁,并且最关键的一点是好用。
最后,从论文中我们可以知道,Unet提出的初衷是为了解决医学图像分割问题,而且unet也确实在这个领域大放异彩,效果非常好,目前大多数医疗影像语义分割任务都会首先用Unet作为baseline。而Unet在医疗图像分隔领域之所以这么好,我感觉是:我们知道浅层卷积关注的是图像的纹理特征,就是关注的是图像的细节点,而深层卷积则关注的是高层语义信息,就是图像的轮廓等更大感受野的信息。但是不管是深层特征还是浅层特征都是有各自的意义的。而医疗影像语义较为简单、结构固定。因此语义信息相比自动驾驶等较为单一,因此并不需要去筛选过滤无用的信息。医疗影像的所有特征都很重要,因此低级特征和高级语义特征都很重要,所以U型结构的skip connection结构(特征拼接)就能更好的派上用场。因为通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回是非常有意义的。
(3)U-Net架构
上图架构是U-Net原论文中的架构图,这个架构相对googlenet和resnet已经非常简单了,所以我也简单介绍一下:
这个架构呈现U型,左边部分就是用传统的卷积层不断实现下采样效果,不断提取图像特征,将图像信息进行压缩,或者说就是enconding的过程;右边部分就是用传统的转置卷积不断地对图像进行上采样,就是decoding的过程;中间的skip connection就是把对应左边的特征图进行crop and copy,就是先crop(因为从架构图上看,很明显左边的特征图尺寸和右边的不一样!所以必须得先crop),然后再concat。
下面的代码是我严格按照上面架构图写的架构代码,完全是我自己的风格写的,所以仅供参考:
import torch
import torch.nn as nn
import torch.nn.functional as F
class downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.down = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, bias=False),nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)
)
def forward(self, x):
return self.down(x)
class upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.up(x)class Unet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.block1 = downsample(1,64) #in(1,572,572)-(64,570, 570)-(64,568,568)
self.maxpool1 = nn.MaxPool2d(2) #out(64, 284,284)
self.block2 = downsample(64, 128) #out(128, 282,282)-(128, 280,280)
self.maxpool2 = nn.MaxPool2d(2) #out(128, 140, 140)
self.block3 = downsample(128, 256) #out(256, 138, 138)-(256, 136, 136)
self.maxpool3 = nn.MaxPool2d(2) #out(256, 68, 68)
self.block4 = downsample(256, 512) #out(512, 66, 66)-(512, 64, 64)
self.maxpool4 = nn.MaxPool2d(2) #out(512,32,32)
self.block5 = downsample(512, 1024) #out(1024,30, 30)-(1024, 28, 28)
self.block6_1 = upsample(1024, 512) #out(512,56, 56)
self.block6_2 = downsample(1024, 512) #in(1024,56,56)-out(512,54, 54)-(512,52,52)
self.block7_1 = upsample(512, 256) #out(256,104, 104)
self.block7_2 = downsample(512, 256) #in(512,104, 104)-out(256,102,102)-(256,100,100)
self.block8_1 = upsample(256, 128) #out(128, 200,200)
self.block8_2 = downsample(256, 128) #in(256,200,200)-out(128,198,198)-(128,196,196)
self.block9_1 = upsample(128, 64) #out(64,392,392)
self.block9_2 = downsample(128, 64) #in(128,392,392)-out(64,390,390)-(64,388,388)
self.block9_3 = nn.Conv2d(64,num_classes,3,1,1) #out(2,388,388)
def forward(self, x):
block1 = self.block1(x) #(64,568,568)
pool1 = self.maxpool1(block1) #(64, 284,284)
block2 = self.block2(pool1) #(128, 280,280)
pool2 = self.maxpool2(block2) #(128, 140, 140)
block3 = self.block3(pool2) #(256, 136, 136)
pool3 = self.maxpool3(block3) #(256, 68, 68)
block4 = self.block4(pool3) #(512, 64, 64)
pool4 = self.maxpool4(block4) #(512,32,32)
block5 = self.block5(pool4) #(1024, 28, 28)
block6_1 = self.block6_1(block5) #(512,56, 56)
block4_ = F.interpolate(block4, 56)
concat1 = torch.cat([block6_1,block4_], dim=1) #(1024,56,56)
block6_2 = self.block6_2(concat1) #(512,52,52)
block7_1 = self.block7_1(block6_2) #(256,104, 104)
block3_ = F.interpolate(block3, 104)
concat2 = torch.cat([block7_1,block3_], dim=1) #(512,104, 104)
block7_2 = self.block7_2(concat2) #(256,100,100)
block8_1 = self.block8_1(block7_2) #(128, 200,200)
block2_ = F.interpolate(block2, 200)
concat3 = torch.cat([block8_1,block2_], dim=1) #(256,200,200)
block8_2 = self.block8_2(concat3) #(128,196,196)
block9_1 = self.block9_1(block8_2) #(64,392,392)
block1_ = F.interpolate(block1, 392)
concat4 = torch.cat([block9_1,block1_], dim=1) #(128,392,392)
block9_2 = self.block9_2(concat4) #(64,388,388)
block9_3 = self.block9_3(block9_2) #(2,388,388)
return block9_3model = Unet(2)
input_data = torch.ones(10, 1, 572, 572)
output = model(input_data)
output.shape运行结果:
 看来从输入到输出是可以顺利跑通的,就也说明架构没问题。
看来从输入到输出是可以顺利跑通的,就也说明架构没问题。
4、语义分隔案例
待续。。。。。