tensorflow实现resnet50(训练+测试+模型转换)
本章使用tensorflow训练resnet50,使用手写数字图片作为数据集。
数据集:
代码工程:
1.train.py
import argparse
import cv2
import tensorflow as tf
# from create_model import resnet_v2_50
from create_model import resnet_v2_50
import numpy as np
from data_loader import get_data, get_data_list
from sklearn.metrics import accuracy_score
def txt_save(data, output_file):
file = open(output_file, 'a')
for i in data:
s = str(i) + '\n'
file.write(s)
file.close()
def get_parms():
parser = argparse.ArgumentParser(description='')
parser.add_argument('--train_data', type=str, default="dataset/train_data.txt")
parser.add_argument('--test_data', type=str, default='data/test/')
parser.add_argument('--checkpoint_dir', type=str, default='./model/')
parser.add_argument('--epoch', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=1)
parser.add_argument('--save_epoch', type=int, default=1)
args=parser.parse_args()
return args
args = get_parms()
inputs=tf.placeholder(tf.float32,(None,28,28,1), name='input_images')
labels = tf.placeholder(tf.int64, [None, 10])
net,endpoins=resnet_v2_50(inputs,10) #['predictions']
# with tf.variable_scope('finetune'):
logit = tf.nn.softmax(net)[0][0]
pred=tf.argmax(logit,1)
correct_predicion=tf.equal(tf.argmax(logit,1),tf.argmax(labels,1))
accuracy=tf.reduce_mean(tf.cast(correct_predicion,'float'))
cross_entropy = tf.losses.softmax_cross_entropy(onehot_labels=labels, logits=logit)
cross_entropy_cost = tf.reduce_mean(cross_entropy)
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy_cost) #Resnet_v2_50和自己构建的模型层都训练
# 开始训练
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
img_list, label_list=get_data_list(args.train_data)
for i in range(args.epoch):
loss_list=[]
acc_list=[]
for j in range(int(len(label_list)/args.batch_size)):
# for j in range(10):
data, true_label=get_data(img_list, label_list, args.batch_size)
_, loss, acc=sess.run([train_step, cross_entropy_cost, accuracy], feed_dict={inputs:data, labels:true_label})
# _=sess.run([train_step], feed_dict={inputs:data, labels:true_label})
# print(loss, acc)
# a,b=sess.run([pred,logit], feed_dict={inputs:data, labels:true_label})
# print(a,b)
print('epoch:',i, 'loss:',np.mean(loss), "acc:", acc)
if i % args.save_epoch==0:
# saver.save(sess,"model/model.ckpt",global_step=i)
saver.save(sess, "model/model")
# tensorboard --logdir=d:/log --host=127.0.0.1
init = tf.initialize_all_variables()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("d:/log/",sess.graph) #目录结构尽量简单,复杂了容易出现找不到文件,原因不清楚
sess.run(init)
# variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
# for i in variables:
# print(i) # 打印
# txt_save(variables, "model/log.txt") # 保存txt 二选一
# import tensorflow as tf
# img_list, label_list=get_data_list(args.train_data)
# data, true_label=get_data(img_list, label_list, args.batch_size)
# with tf.Session() as sess:
# saver = tf.train.import_meta_graph('model/model.meta')
# saver.restore(sess,tf.train.latest_checkpoint('model/'))
# pred,logit=sess.run([pred,logit], feed_dict={inputs:data, labels:true_label})
# print(pred)
# ##Model has been restored. Above statement will print the saved value
2.create_model.py
import tensorflow as tf
import os
import numpy as np
import cv2
import argparse
def model(inputs):
w1=tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
w2=tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
w3=tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=0.01))
w4=tf.Variable(tf.random_normal([2048, 625], stddev=0.01))
w5=tf.Variable(tf.random_normal([625, 10], stddev=0.01))
l1_conv=tf.nn.conv2d(inputs, w1, strides=[1, 1, 1, 1], padding='SAME')
l1_relu=tf.nn.relu(l1_conv)
l1_pool=tf.nn.max_pool(l1_relu, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
l1_drop = tf.nn.dropout(l1_pool, 0.5)
l2_conv=tf.nn.conv2d(l1_drop, w2, strides=[1, 1, 1, 1], padding='SAME')
l2_relu=tf.nn.relu(l2_conv)
l2_pool=tf.nn.max_pool(l2_relu, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
l2_drop = tf.nn.dropout(l2_pool, 0.5)
l3_conv=tf.nn.conv2d(l2_drop, w3, strides=[1, 1, 1, 1], padding='SAME')
l3_relu=tf.nn.relu(l3_conv)
l3_pool=tf.nn.max_pool(l3_relu, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
l3_out = tf.reshape(l3_pool, [-1, 2048])
l3_drop = tf.nn.dropout(l3_out, 0.5)
l4 = tf.nn.relu(tf.matmul(l3_drop, w4))
l4 = tf.nn.dropout(l4, 0.5)
out = tf.matmul(l4, w5)
return out
def model2(inputs):
w1=tf.Variable(tf.random_normal([5, 5, 1, 6], stddev=0.01))
b1 = tf.Variable(tf.truncated_normal([6]))
w2=tf.Variable(tf.random_normal([5, 5, 6, 16], stddev=0.01))
b2 = tf.Variable(tf.truncated_normal([16]))
w3=tf.Variable(tf.random_normal([5, 5, 16, 120], stddev=0.01))
b3 = tf.Variable(tf.truncated_normal([120]))
w4 = tf.Variable(tf.truncated_normal([7 * 7 * 120, 80]))
b4 = tf.Variable(tf.truncated_normal([80]))
w5 = tf.Variable(tf.truncated_normal([80, 10]))
b5 = tf.Variable(tf.truncated_normal([10]))
l1_conv=tf.nn.conv2d(inputs, w1, strides=[1, 1, 1, 1], padding='SAME')
l1_sigmoid=tf.nn.sigmoid(l1_conv+b1)
l1_pool=tf.nn.max_pool(l1_sigmoid, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
l2_conv=tf.nn.conv2d(l1_pool, w2, strides=[1, 1, 1, 1], padding='SAME')
l2_sigmoid=tf.nn.sigmoid(l2_conv+b2)
l2_pool=tf.nn.max_pool(l2_sigmoid, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
l3_conv=tf.nn.conv2d(l2_pool, w3, strides=[1, 1, 1, 1], padding='SAME')
l3_sigmoid=tf.nn.sigmoid(l3_conv+b3)
l3_out = tf.reshape(l3_sigmoid, [-1, 7*7*120])
l4 = tf.nn.sigmoid(tf.matmul(l3_out, w4)+b4)
out = tf.nn.softmax(tf.matmul(l4, w5) + b5)
return out
from datetime import datetime
import time
import math
import collections
import tensorflow as tf
slim = tf.contrib.slim
# 使用collections.namedtuple设计ResNet的Block模块
# scope参数是block的名称
# unit_fn是功能单元(如残差单元)
# args是一个列表,如([256, 64, 1]) X 2 + [256, 64, 2]),代表两个(256, 64, 1)单元
# 和一个(256, 64, 2)单元
Block = collections.namedtuple("Block", ['scope', 'unit_fn', 'args'])
# 定义下采样的方法,通过max_pool2d实现
def subsample(inputs, factor, scope=None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
# 定义一个创建卷积层的函数
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1,
padding='SAME', scope=scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride,
padding='VALID', scope=scope)
# 定义堆叠的block函数
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections=None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net,
depth=unit_depth,
depth_bottleneck=unit_depth_bottleneck,
stride=unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name,net)
return net
# 用于设定默认值
def resnet_arg_scope(is_training=True,
weight_decay=0.0001,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params
):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
return arg_sc
# 定义残差学习单元
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride,
outputs_collections=None, scope=None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu,
scope='preact')
# shortcut为直连的X
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride,
scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None,
scope='conv3')
# 将直连的X加到残差上,得到output
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections,
sc.name, output)
# 定义ResNet的主函数
def resnet_v2(inputs,
blocks,
num_classes=None,
global_pool=True,
include_root_block=True,
reuse=None,
scope=None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck,stack_blocks_dense],outputs_collections=end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn=None,normalizer_fn=None):
net = conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,normalizer_fn=None, scope='logits')
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points
# 定义50层的ResNet
def resnet_v2_50(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_50'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,include_root_block=True, reuse=reuse, scope=scope)3.data_loader.py
import cv2
import os
import numpy as np
import random
# f1=open('dataset/train_data.txt','w+')
# path='dataset/'
# for file in os.listdir(path):
# if file.endswith('png'):
# line=path+file+' 1'+'\n'
# f1.write(line)
# print(line)
def one_hot(data, num_classes):
return np.squeeze(np.eye(num_classes)[data.reshape(-1)])
def get_data_list(path):
f1=open(path,'r')
lines=f1.readlines()
img_list=[]
label_list=[]
for line in lines:
label=int(line.strip().split(" ")[1])
label=one_hot(np.array(label),10)
label_list.append(label)
file_name=line.strip().split(" ")[0]
img=cv2.imread(file_name, 0)
img=np.reshape(img,[28,28,1])
# print(img.shape)
img_list.append(img)
return img_list, label_list
def get_data(img_list, label_list, batch_size):
lens=len(label_list)
random_nums=random.sample(range(lens),lens)
nums=random_nums[0:batch_size]
# print(nums)
data=[]
label=[]
for index in nums:
data.append(img_list[index])
label.append(label_list[index])
return np.array(data), np.array(label)
# batch_size=1
# path="dataset/mnist/train/train_data.txt"
# img_list, label_list=get_data_list(path)
# print(len(img_list), len(label_list))
# data, label=get_data(img_list, label_list, batch_size)
# print(type(data[0]),label)4.查看ckpt网络.py
from tensorflow.python import pywrap_tensorflow
import os
import tensorflow as tf
from tensorflow.python.platform import gfile
# checkpoint_path = os.path.join('model/model.ckpt')
# reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path)
# var_to_shape_map = reader.get_variable_to_shape_map()
# for key in var_to_shape_map:
# print('tensor_name: ', key)
ckpt_path = os.path.join('model/model')
saver = tf.train.import_meta_graph(ckpt_path+'.meta',clear_devices=True)
graph = tf.get_default_graph()
with tf.Session( graph=graph) as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess,ckpt_path)
# tensorboard --logdir=d:/log --host=127.0.0.1
init = tf.initialize_all_variables()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("d:/log/",sess.graph) #目录结构尽量简单,复杂了容易出现找不到文件,原因不清楚
sess.run(init)5.ckpt2pb.py
import tensorflow as tf
from tensorflow.python.framework import graph_util
from tensorflow.python import pywrap_tensorflow
def freeze_graph(cpkt_path, pb_path):
checkpoint = tf.train.get_checkpoint_state("model") #检查目录下ckpt文件状态是否可用
cpkt_path2 = checkpoint.model_checkpoint_path #得ckpt文件路径
print("gg:",checkpoint,cpkt_path2)
# 指定输出的节点名称,该节点名称必须是原模型中存在的节点
output_node_names = "resnet_v2_50/logits/BiasAdd"
saver = tf.train.import_meta_graph(cpkt_path + '.meta', clear_devices=True)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
# feature_data_list = input_graph_def.get_operation_by_name('resnet_v2_50/conv1').outputs[0]
# input_image=tf.placeholder(None,28,28,1)
with tf.Session() as sess:
saver.restore(sess, cpkt_path) # 恢复图并得到数据
pb_path_def = graph_util.convert_variables_to_constants( # 模型持久化,将变量值固定
sess=sess,
input_graph_def=input_graph_def, # 等于:sess.graph_def
output_node_names=output_node_names.split(",")) # 如果有多个输出节点,以逗号隔开
# print(pb_path_def)
with tf.gfile.GFile(pb_path, 'wb') as fgraph:
fgraph.write(pb_path_def.SerializeToString())
# with tf.io.gfile.GFile(pb_path, "wb") as f: # 保存模型
# f.write(pb_path_def.SerializeToString()) # 序列化输出
print("%d ops in the final graph." % len(pb_path_def.node)) # 得到当前图有几个操作节点
if __name__ == '__main__':
# 输入路径(cpkt)
cpkt_path = 'model/model'
# 输出路径(pb模型)pb_path_def
pb_path = "model/test.pb"
# 模型转换
freeze_graph(cpkt_path, pb_path)
# # 查看节点名称:
# reader = pywrap_tensorflow.NewCheckpointReader(cpkt_path)
# var_to_shape_map = reader.get_variable_to_shape_map()
# for key in var_to_shape_map:
# print("tensor_name: ", key)
# # 查看某个指定节点的权重
# reader = pywrap_tensorflow.NewCheckpointReader(cpkt_path)
# var_to_shape_map = reader.get_variable_to_shape_map()
# w0 = reader.get_tensor("finetune/dense_1/bias")
# print(w0.shape, type(w0))
# print(w0[0])
# with tf.Session() as sess:
# # 加载模型定义的graph
# saver = tf.train.import_meta_graph('model/model.meta')
# # 方式一:加载指定文件夹下最近保存的一个模型的数据
# saver.restore(sess, tf.train.latest_checkpoint('model/'))
# # 方式二:指定具体某个数据,需要注意的是,指定的文件不要包含后缀
# # saver.restore(sess, os.path.join(path, 'model.ckpt-1000'))
# # 查看模型中的trainable variables
# tvs = [v for v in tf.trainable_variables()]
# for v in tvs:
# print(v.name)
# # print(sess.run(v))
# # # 查看模型中的所有tensor或者operations
# # gv = [v for v in tf.global_variables()]
# # for v in gv:
# # print(v.name)
# # # 获得几乎所有的operations相关的tensor
# # ops = [o for o in sess.graph.get_operations()]
# # for o in ops:
# # print(o.name)6.pb2pbtxt.py (pb和pbtxt互转,修改input_shape)
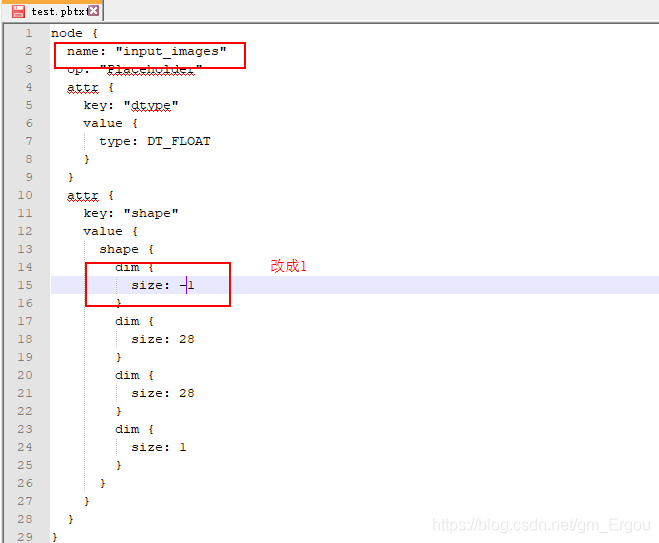
修改pbtxt文件,把动态shape改成静态的,再转回pb模型
import tensorflow as tf
from tensorflow.python.platform import gfile
from google.protobuf import text_format
def convert_pb_to_pbtxt(root_path, pb_path, pbtxt_path):
with gfile.FastGFile(root_path+pb_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
tf.train.write_graph(graph_def, root_path, pbtxt_path, as_text=True)
return
def convert_pbtxt_to_pb(root_path, pb_path, pbtxt_path):
with tf.gfile.FastGFile(root_path+pbtxt_path, 'r') as f:
graph_def = tf.GraphDef()
file_content = f.read()
# Merges the human-readable string in `file_content` into `graph_def`.
text_format.Merge(file_content, graph_def)
tf.train.write_graph(graph_def, root_path, pb_path, as_text=False)
return
if __name__ == '__main__':
# 模型路径
root_path = "model/"
pb_path = "test.pb"
pbtxt_path = "test.pbtxt"
# 模型转换
convert_pb_to_pbtxt(root_path, pb_path, pbtxt_path)
# convert_pbtxt_to_pb(root_path, pb_path, pbtxt_path)7.test_pb.py
import tensorflow as tf
from tensorflow.python.framework import graph_util
from tensorflow.python import pywrap_tensorflow
import numpy as np
def recognize(jpg_path, pb_file_path):
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
with open(pb_file_path, "rb") as f:#主要步骤即为以下标出的几步,1、2步即为读取图
output_graph_def.ParseFromString(f.read())# 1.将模型文件解析为二进制放进graph_def对象
_ = tf.import_graph_def(output_graph_def, name="")# 2.import到当前图
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
graph = tf.get_default_graph()# 3.获得当前图
# # 4.get_tensor_by_name获取需要的节点
# x = graph.get_tensor_by_name("IteratorGetNext_1:0")
# y_out = graph.get_tensor_by_name("resnet_v1_50_1/predictions/Softmax:0")
x = graph.get_tensor_by_name("input_images:0")
y_out = graph.get_tensor_by_name("resnet_v2_50/logits/BiasAdd:0")
img=np.random.normal(size=(1, 28, 28, 1))
# img=cv2.imread(jpg_path)
# img=cv2.resize(img, (224, 224))
# img=np.reshape(img,(1,224,224,3))
# print(img.shape)
#执行
output = sess.run(y_out, feed_dict={x:img})
pred=np.argmax(output[0][0], axis=1)
print("预测结果:", output.shape, output, "预测label:", pred)
# prediction_labels = np.argmax(test_y_out, axis=2)
# print(prediction_labels.shape, prediction_labels)
recognize("dataset/00000.PNG", "model/test.pb")