批量截掉MP3文件的固定时间的python代码(亲测贼好用哦)
有这么一个需求,就是听某个系列的讲课,每个课程前都有101秒的前奏介绍,每一次听的时候都要忍受这101秒的时间,既然学了python ,就把它解决掉。话不多说,上代码干货!
from pydub import AudioSegment
import os
from multiprocessing import Pool
def worker(filename):
try:
# print(filename)
path = r'F:\\55后\\57-114\\test\\'
# print(path)
path_out = path + '转换后\\'
print(path_out)
if not os.path.exists(path_out):
os.mkdir(path_out)
used_name = path + filename
print(used_name)
## 因为文件名里面包含了文件的后缀,所以重命名的时候要加上
new_name = path_out + filename
input_music = AudioSegment.from_mp3(used_name)
# 截取音频前101000毫秒(101秒)
output_music = input_music[101000:]
# 保存音频 前面为保存的路径wenj ,后面为保存的格式
output_music.export(new_name, bitrate="64k")
print(new_name+'完成!')
except:
## 跳过一些系统隐藏文档
pass
# os.rename(used_name, new_name)
if __name__ == '__main__':
path = r'F:\\55后\\57-114\\test\\'
converted_count = 0
convertlist = []
for filename in os.listdir(path):
if filename.endswith(".mp3"):
convertlist.append(filename)
converted_count += 1
print(convertlist)
p = Pool(processes=min(converted_count, os.cpu_count()))
p.map(worker, convertlist)
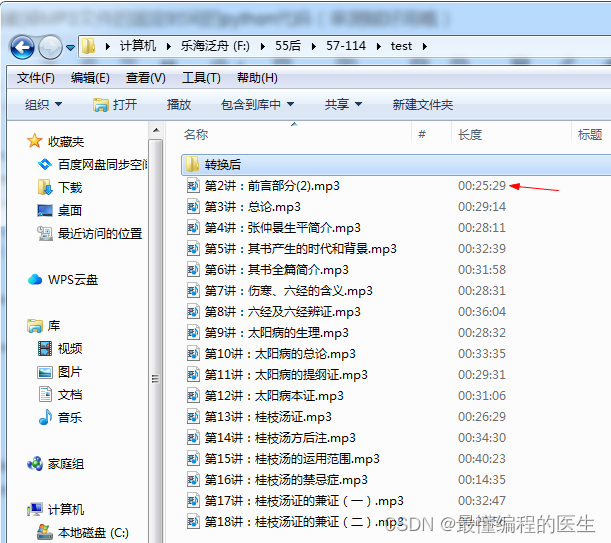
转换前文件长度:
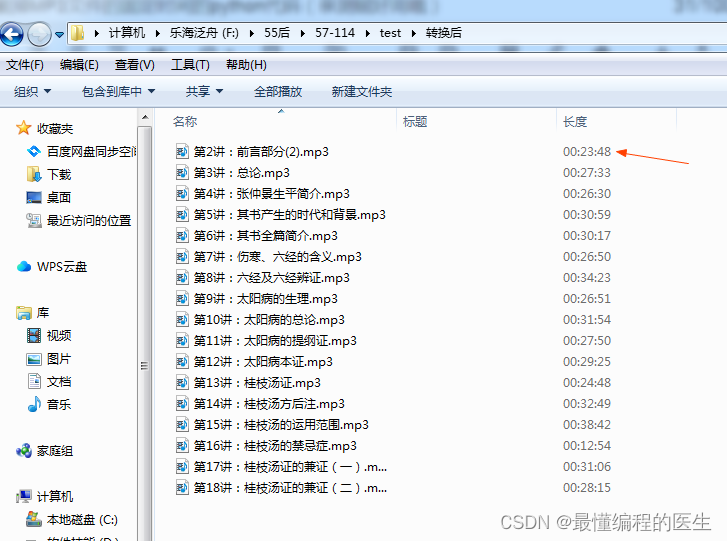
转换后文件长度:
from pydub import AudioSegment
关于配置AudioSegment模块,这里不多说明,请自行搜索其他相关文档。