嵌入式-C语言-9-Makefile/结构体/联合体
一、Makefile
1.1.问:如果项目产品代码有1万源文件.c,编译极其的繁琐
gcc -o main main.c a.c b.c .... 一个万.c
这么简化程序的编译呢?
答:必须只能利用Makefile来实现
1.2.Makefile功能:能够制定编译规则,将来让gcc编译器根据这个规则来编译程序,Makefile本质就是一个文本文件,此文件给make命令使用,将来make命令会根据Makefile里面的编译规则让gcc编译程序。
1.3.Makefile语法格式:
目标:依赖1 依赖2 依赖3 ....依赖N
(TAB键)编译命令1
(TAB键)编译命令2
...
(TAB键)编译命令N
(TAB键) 还可以是其他命令:ls/cp/cd等
注意:Makefile注释用#
例如:目标是把helloworld.c编译生成helloworld
vim Makfile 添加
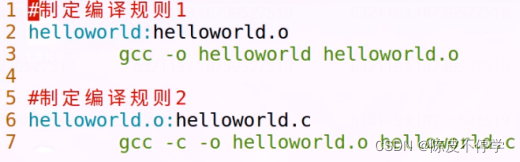
#指定规则:一步到位
helloworld:helloworld.c
gcc -o helloworld helloworld.c
#或者
#指定规则1:分步
helloworld:helloworld.o
gcc -o helloworld helloworld.o
#指定规则2:
helloworld.o:helloworld.c
gcc -c -o helloworld.o helloword.c
案例:利用Makefile编译helloworld.c文件
vim helloworld.c
vim Makefile
make //编译程序
./helloworld
make //编译提示helloworld是最新的
vim helloworld.c //修改源文件
ls -lh //查看helloworld.c和helloworld的时间戳
make //又重新编译
先检查有没有helloworld文件,如果有,就检查helloworld.c文件的时间戳是不是比他新,如果helloworld.c文件比helloworld文件新,就重新编译,反之不更新,如果没有helloworld文件,就按编译规则来。
1.4.Makefile工作原理
当执行make命令时,make命令首先在当前目录下找Makefile,一旦找到Makfile文件,打开此文件并且找到所有的编译规则,通过这些编译规则确定了最终的目标是helloworld和源文件helloworld.c,然后make命令首先在当前目录下找是否存在目标文件helloworld,如果helloworld存在,然后检查helloworld和helloworld.c的时间戳哪个更新,如果helloworld的时间戳比helloworld.c新,说明源文件没有改过,无需编译,提示文件最新,如果helloworld的时间戳比helloworld.c要旧,说明helloworld.c修改过,根据编译规则的命令重新编译,如果一开始没有找到helloworld,程序整个重新编译
1.5.Makefile小技巧
%.o:%.c
(TAB键)gcc -c -o $@ $<
说明:
%.o:目标文件.o
%.c:源文件.c
$@:目标文件
$<:源文件
作用是将当前目录下所有的.c文件单独编译生成对应的.o目标文件
二、复合类型之结构体
2.1.目前C程序分配内存的方法两种:定义变量和定义数组
定义变量的缺陷:不能大量定义,所以诞生数组
定义数组的缺陷:数据类型是相同的,所以诞生结构体
问:什么场合需要定义大量变量和变量的数据类型不相同呢?
答:比如让计算机记录或者描述一个学生的信息
学生的信息如下:
int age; //年龄
char *name ;//名字
int id; //学号
float score; //学分
显然变量的数据类型不一致,数组无法做到,采用结构体.
2.2.结构体特点:能够包含大量的变量并且对变量的数据类型无要求
对应的关键字:struct
结构体也是一种数据类型,它是程序员自行定义的一种数据类型,类比成一个int类型,结构体分配的内存是连续的,一个成员挨着一个成员
2.3.结构体声明定义的使用方法:
a)方法1:直接定义结构体变量(很少用)
1.语法:struct {
结构体成员; //又称结构体字段
}结构体变量名;
2.例如:描述学生信息
//定义一个学生信息的结构体变量student1
struct {
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
}student1;
//再定义一个学生信息的结构体变量student2
struct {
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
}student2;3.缺陷:每次定义一个结构体变量,结构体成员都要重新写一遍,很繁琐
b)方法2:先声明结构体数据类型, 然后用这种结构体数据类型定义结构体变量(常用,掌握)
1.声明结构体数据类型的语法:
struct 结构体名 {
结构体成员;
};
注意:不会分配内存 大型程序,结构体声明放到头文件来写
2.用结构体数据类型定义结构体变量的语法:
struct 结构体名 结构体变量名;
注意:会分配内存 大型程序,结构体定义放到源文件中来写
3.例如:
//1.声明描述学生信息的结构体数据类型
struct student {
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
};//2.定义两个学生信息的结构体变量
struct student student1;
struct student studnet2;
//或者
struct student student1, student2;4.缺陷:每次定义结构体变量,struct 结构体名每次都要书写,很烦躁!
c)方法3:先用typedef关键字给一个声明的结构体数据类型取别名(外号),然后用别名定义结构体变量(实际开发最常用)
1)务必掌握typedef关键字
功能:给数据类型取别名(外号)
语法:typedef 原数据类型 别名;
例如:对于基本数据类型取别名(实际开发代码)
typedef char s8; //s=signed:有符号,8:8位
typedef unsigned char u8; //u=unsiged
typedef short s16;
typedef unsigned short u16;
typedef int s32;
typedef unsigned int u32;
typedef long long s64;
typedef unsigned long long u64;
typedef float f32;
typedef double f64;
//使用:
int a 写成 s32 a;
unsigned char b 写成 u8 b2.用typedef对声明的结构体取别名
注意:规定:别名后面加_t,对于大型程序写头文件(不成文规定)
形式1:
语法:typedef struct {
结构体成员;
}别名_t;
例如:
typedef struct {
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
}stu_t;形式2:
语法:typedef struct 结构体名{
结构体成员;
}别名_t;
例如:
typedef struct studnet{
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
}stu_t;形式3:
struct studnet{
int age; //描述学生的年龄
int id; //描述学生的学号
float score; //描述学生的学分
char name[30]; //描述学生的姓名
int weight; //学生的体重
};
//取别名
typedef struct student stu_t;3.不管使用哪种typedef对结构体数据类型取别名,定义结构体变量都一样
定义结构体变量语法:别名 结构体变量名;
例如:定义两个学生信息的结构体变量
stu_t student1;
stu_t student2;
或者:
stu_t student1, student2;
2.4.结构体变量的初始化方式,两种方式:
a)传统初始化方式:
1.语法:struct 结构体名/别名 结构体变量名 = {初始化的值};
2.例如:
struct student student1 = {18, 666, 100, "哥", 128};
//或者
stu_t student1 = {18, 666, 100, "哥"};3.缺陷:定义初始化的时候需要按照顺序全部初始化,因为有些场合可以不用按照顺序,关键是可以不用全部初始化
b)标记初始化方式:
1.语法:struct 结构体名/别名 结构体变量名 = {
.某个成员名 = 初始化值,
.某个成员名 = 初始化值,
... };
2.例如:
struct student student1 = {
.name = "哥",
.weight = 128,
.age = 18,
};
//或者
stu_t student1 = {
.name = "哥",
.weight = 128,
.age = 18,
};3.特点:不用按照顺序,不用全部成员初始化
2.5.结构体变量成员的访问:两种形式
a)通过"."运算符来访问结构体变量的成员
语法:结构体变量名.成员名; //将来可以访问这个成员的内存区域
例如:
stu_t student1 = {
.name = "哥",
.weight = 128,
.age = 18,
};
//读查看
printf("%s %d %d\n",
student1.name, student1.weight, student1.age);
//写修改
strcpy(student1.name, "弟");
student1.weight = 821;
student1.age = 17; b)通过"->"运算符来访问结构体指针变量的成员
语法:结构体指针变量名->成员名; //将来可以访问这个成员的内存区域
例如:
stu_t student1 = {
.name = "哥",
.weight = 128,
.age = 18,
};
stu_t *p = &student1; //定义一个结构体指针变量p指向student1结构体变量
//读查看
printf("%s %d %d\n",
p->name, p->weight, p->age
strcpy(p->name, "弟");
p->weight = 821;
p->age = 17; 2.6.结构体变量之间可以直接赋值
例如:
stu_t student1 = {18, 666, 100, "哥", 128};
stu_t student2 = student1;
或者
stu_t student1 = {18, 666, 100, "哥", 128};
stu_t *p = &student1; //p指向student1
stu_t student2 = *p;
2.7.结构体嵌套:结构体成员还是一个结构体
例如:
//声明描述学生出生日期的结构体
typedef struct birthday {
int year; //年
int month; //月
int date; //日
}birthday_t;
//声明描述学生信息的结构体
typedef struct student {
char name[30]; //姓名
int age; //年龄
//struct birthday birth; //学生的出生日期
birthday_t birth; //学生的出生日期
};2.8.函数的形参是结构体,两种形式
a)直接传递结构体变量本身,形参是实参的一份拷贝,结构体有多大就需要拷贝多大,函数通过形参是不能修改结构体实参,只是对形参做了改变
b)直接传递结构体变量的地址,函数通过形参可以直接修改结构体实参,代码执行效率高,如果是指针只需拷贝4字节
c)公式,规矩:如果函数要访问结构体,将来要传递结构体指针,不要传递结构体变量,如果函数对结构体成员不进行修改,形参用const修饰
void show(const stu_t *pst)
{
printf("%s\n", pst->name);
//不让修改:strcpy(pst->name, "蛋");
}
void grow(stu_t *pst)
{
pst->age++;
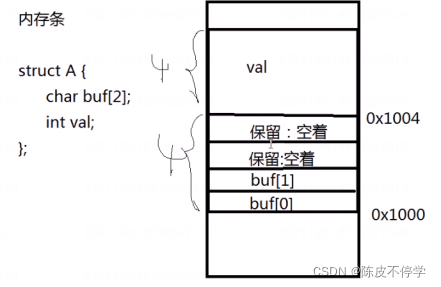
}2.9.结构体内存对齐问题
a)gcc对结构体成员编译时,默认按4字节对齐
例如:
struct A {
char buf[2];
int val;
};
结果:sizeof(struct A) = 8
内存分布图:
b)演示代码:
/*结构体内存对齐*/
#include <stdio.h>
//声明结构体数据类型A
struct A {
char buf[2]; //4
int val; //4
};
//声明结构体数据类型B
struct B {
char c; //4
short s[2]; //4
int i; //4
};
#pragma pack(1) //让gcc强制从这个地方开始后面代码按照1字节对齐方式编译
//声明结构体类型C
struct C {
char c; //1
short s[2]; //4
int i; //4
};
#pragma pack() //让gcc到这里在恢复成默认4字节对齐
//声明结构体类型D
struct D {
int i; //4
char c; //4
};
//声明结构体类型E
struct E {
double d; //8
char c; //4
};
int main(void)
{
printf("sizeof(struct A) = %d\n", sizeof(struct A)); //8
printf("sizeof(struct B) = %d\n", sizeof(struct B)); //12
printf("sizeof(struct C) = %d\n", sizeof(struct C)); //9
printf("sizeof(struct D) = %d\n", sizeof(struct D)); //8
printf("sizeof(struct E) = %d\n", sizeof(struct E)); //12
return 0;
}三、联合体
3.1.特点:
a)它和结构体使用语法一模一样,只是将关键字struct换成union
b)联合体中所有成员是共用一块内存,优点节省内存
c)联合体占用的内存按成员中占内存最大的来算例如:
union A {
char a;
short b;
int c;
};
sizeof(union A) = 4;d)初始化问题
union A a = {8}; //默认给第一个成员a,a = 8
union A a = {.c = 8} //强制给c赋值
3.2.经典笔试题
现象:
1.X86架构的CPU为小端模式:数据的低位在内存的低地址,数据的高位在内存的高地址处
例如:
int a = 0x12345678;
内存条
低地址 高地址
0-------1-----2-------3------4--------------------------------->
0x78 0x56 0x34 0x12
2.POWERPC架构的CPU为大端模式:
数据的低位在内存的高地址,数据的高位在内存的低地址处
例如:
int a = 0x12345678;
内存条
低地址 高地址
0-------1-----2-------3------4--------------------------------->
0x12 0x34 0x56 0x78
要求:编写一个程序求当前处理器是X86架构还是POWERPC架构
思路:采用union或者指针
提示:
union A {
char a;
int b;
};
参考代码:
#include <stdio.h>
//声明一个联合体
typedef union w
{
int a; //4 字节
char b; //1 字节
} c_t;
int main(void)
{
//定义联合体变量
c_t c.a=1;
if (c.b==1)
printf("小端\nn");
else
printf("大端\n");
return 1;
}