逻辑回归(Logistic Regression)测试实例:糖尿病预测项目(不调库,手工推)
一、数据来源
1.数据来源:kaggle
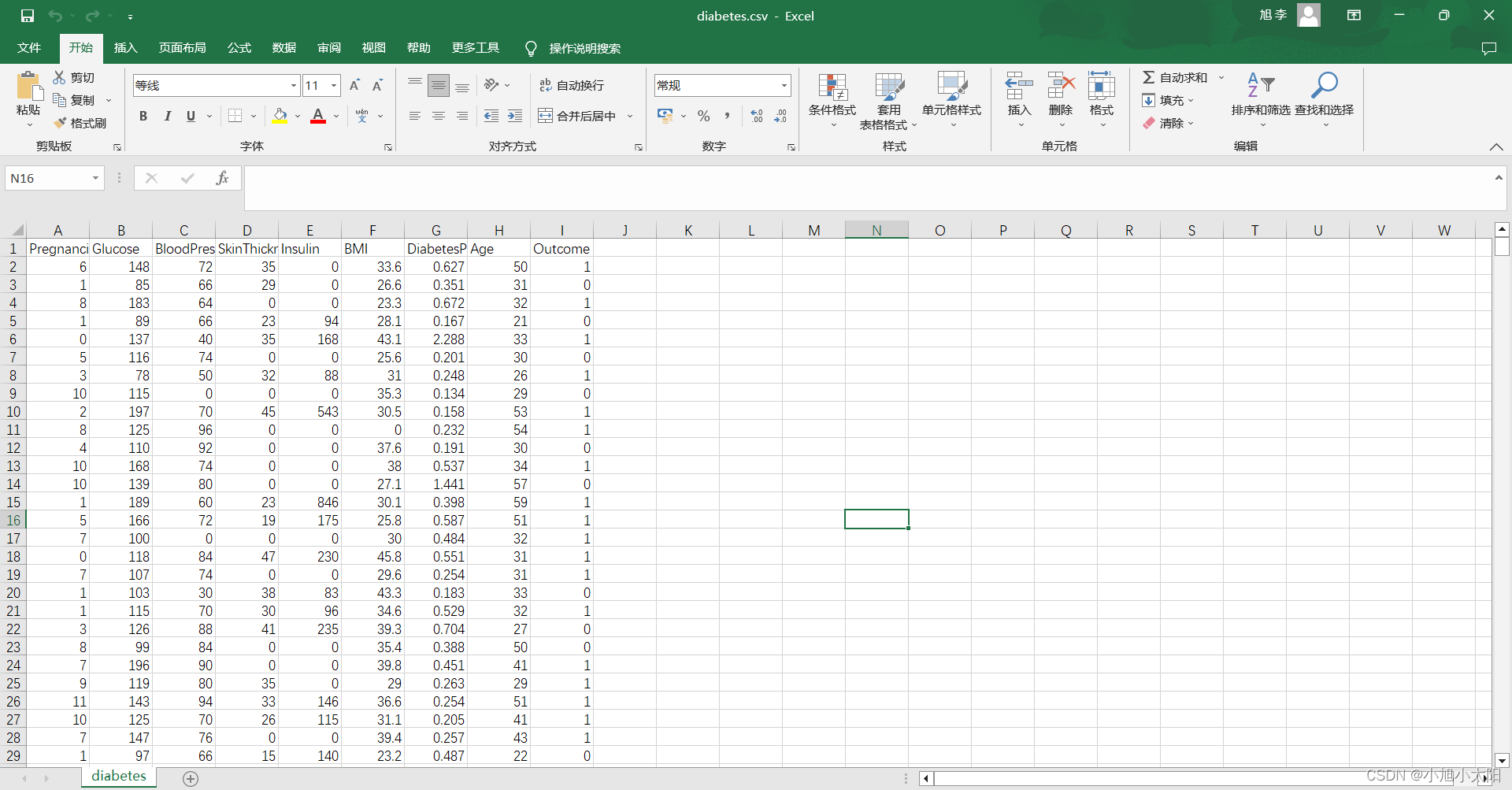
2.数据样式
通过模型训练后,对测试集的前5列(Pregnancies、Glucose、BloodPressure、SkinThickness、Insulin、BMI、DiabetesPedigreeFunction、Age)数据进行预测,判断最后一列(Outcome)的数值,1表示患病,0表示未患病
二.使用方法
逻辑回归(Logistic Regression)
方法说明:
逻辑回归函数: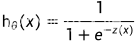
其中: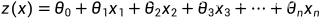
损失函数: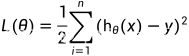
梯度下降法: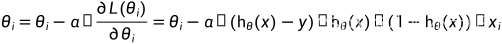
其中: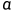 为自定义的学习比率
为自定义的学习比率
三.代码实现
从数据读取开始,不调取三方库,纯手工推。
导入基础库
from random import seed,randrange
from csv import reader
from math import exp读取csv文件,将字符串内容转换为浮点型
def csv_loader(file):
dataset=[]
with open(file,'r') as f:
csv_list=reader(f)
for row in csv_list:
if not row:
continue
dataset.append(row)
return dataset
def str_to_float_converter(dataset):
dataset=dataset[1:]
for i in range(len(dataset[0])):
for row in dataset:
row[i]=float(row[i].strip(''))数据标准化(Min-Max标准化)
因为数据之间的量纲不一样,需要进行无量纲处理。
def min_max(dataset):
min_max_list=[]
for i in range(len(dataset[0])):
col_value=[row[i] for row in dataset]
min_value=min(col_value)
max_value=max(col_value)
min_max_list.append([min_value,max_value])
return min_max_list
def normalization(dataset):
min_max_list=min_max(dataset)
for i in range(len(dataset[0])):
for row in dataset:
row[i]=(row[i]- min_max_list[i][0])/(min_max_list[i][1]-min_max_list[i][0])数据拆分
通过k-fold cross validation对数据进行拆分。
def k_fold_cross_validation(dataset,n_folds):
dataset_splitted=[]
copy_dataset=list(dataset)
every_fold_size=int(len(dataset)/n_folds)
for i in range(n_folds):
datas_fold=[]
while len(datas_fold) < every_fold_size:
index=randrange(len(copy_dataset))
datas_fold.append(copy_dataset.pop(index))
dataset_splitted.append(datas_fold)
return dataset_splitted计算模型的准确性
如果预测的数值和真实的数值相等,每一个相等,就正确记录一次;
最后计算准确率。
def calculate_accuracy(actual_data,predicted_data):
correct_num=0
for i in range(len(actual_data)):
if actual_data[i] == predicted_data[i]:
correct_num+=1
return correct_num/float(len(actual_data)) *100设置模型测试
使用K折交叉验证,评估每一次折叠的模型准确性,准确性越接近1,模型拟合得就越好。
其中:algo为算法占位,具体算法写好后,在运行时迭代即可。
def model_test(dataset,algo,n_folds,*args):
folds=k_fold_cross_validation(dataset,n_folds)
scores=[]
for fold in folds:
traning_dataset=list(folds)
traning_dataset.remove(fold)
traning_dataset=sum(traning_dataset,[])
testing_dataset=[]
for row in fold:
testing_dataset.append(row)
predicted_data=algo(traning_dataset,testing_dataset,*args)
actual_data=[row[-1] for row in testing_dataset]
accuracy=calculate_accuracy(actual_data,predicted_data)
scores.append(accuracy)
return scores预测数据的基础模型
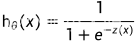 ,
,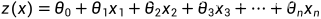
def prediction(row,coe):
z_hat = coe[0]
for i in range(len(row)-1):
z_hat +=coe[i+1]*row[i]
y_hat=1/(1+exp(-z_hat))
return y_hat预估系数(coefficient)
通过随机梯度下降法,不断迭代,寻找最优的coefficient.
def estimate_coe(traning_dataset,learning_rate,n_epochs):
coe=[0.0 for i in range(len(traning_dataset[0]))]
for epoch in range(n_epochs):
sum_error=0
for row in traning_dataset:
y_hat = prediction(row,coe)
error = y_hat -row[-1]
sum_error += error**2
coe[0] = coe[0] - learning_rate* error * y_hat * (1.0- y_hat)
for i in range(len(row)-1):
coe[i+1] = coe[i+1] - learning_rate* error * y_hat * (1- y_hat) *row[i]
print('This is epoch < %s >, sum_error is <%.3f>' %(epoch,sum_error))
return coe逻辑回归函数,用于对测试数据预测
def logistic_regression(traning_dataset,testing_dataset,learning_rate,n_epochs):
predictions=[]
coe=estimate_coe(traning_dataset,learning_rate,n_epochs)
for row in testing_dataset:
y_hat = round(prediction(row,coe))
predictions.append(y_hat)
return predictions运行和参数调整
seed(999)
file='./download_datas/diabetes.csv'
dataset=csv_loader(file)
str_to_float_converter(dataset)
dataset=dataset[1:]
normalization(dataset)
algo=logistic_regression
n_folds=5
learning_rate=0.1
n_epochs=1000
scores=model_test(dataset,algo,n_folds,learning_rate,n_epochs)
print('The scores of my model are : %s ' %(scores))
print('The average of scores is %.3f%%' %(sum(scores)/len(scores)))运行结果
The scores of my model are : [69.93464052287581, 82.35294117647058, 83.66013071895425, 75.16339869281046, 75.16339869281046]
The average of scores is 77.255%四.完整代码
#1.导入基础库
from random import seed,randrange
from csv import reader
from math import exp
#2.读取csv文件,将字符串内容转换为浮点型
def csv_loader(file):
dataset=[]
with open(file,'r') as f:
csv_list=reader(f)
for row in csv_list:
if not row:
continue
dataset.append(row)
return dataset
def str_to_float_converter(dataset):
dataset=dataset[1:]
for i in range(len(dataset[0])):
for row in dataset:
row[i]=float(row[i].strip(''))
#3.数据标准化(Min-Max 标准化)
def min_max(dataset):
min_max_list=[]
for i in range(len(dataset[0])):
col_value=[row[i] for row in dataset]
min_value=min(col_value)
max_value=max(col_value)
min_max_list.append([min_value,max_value])
return min_max_list
def normalization(dataset):
min_max_list=min_max(dataset)
for i in range(len(dataset[0])):
for row in dataset:
row[i]=(row[i]- min_max_list[i][0])/(min_max_list[i][1]-min_max_list[i][0])
#4.数据拆分
def k_fold_cross_validation(dataset,n_folds):
dataset_splitted=[]
copy_dataset=list(dataset)
every_fold_size=int(len(dataset)/n_folds)
for i in range(n_folds):
datas_fold=[]
while len(datas_fold) < every_fold_size:
index=randrange(len(copy_dataset))
datas_fold.append(copy_dataset.pop(index))
dataset_splitted.append(datas_fold)
return dataset_splitted
#5.计算模型的准确性
def calculate_accuracy(actual_data,predicted_data):
correct_num=0
for i in range(len(actual_data)):
if actual_data[i] == predicted_data[i]:
correct_num+=1
return correct_num/float(len(actual_data)) *100
#6.设置模型测试
def model_test(dataset,algo,n_folds,*args):
folds=k_fold_cross_validation(dataset,n_folds)
scores=[]
for fold in folds:
traning_dataset=list(folds)
traning_dataset.remove(fold)
traning_dataset=sum(traning_dataset,[])
testing_dataset=[]
for row in fold:
testing_dataset.append(row)
predicted_data=algo(traning_dataset,testing_dataset,*args)
actual_data=[row[-1] for row in testing_dataset]
accuracy=calculate_accuracy(actual_data,predicted_data)
scores.append(accuracy)
return scores
#7.预测数据的基础模型
def prediction(row,coe):
z_hat = coe[0]
for i in range(len(row)-1):
z_hat +=coe[i+1]*row[i]
y_hat=1/(1+exp(-z_hat))
return y_hat
#8.预估系数(coefficient)
def estimate_coe(traning_dataset,learning_rate,n_epochs):
coe=[0.0 for i in range(len(traning_dataset[0]))]
for epoch in range(n_epochs):
sum_error=0
for row in traning_dataset:
y_hat = prediction(row,coe)
error = y_hat -row[-1]
sum_error += error**2
coe[0] = coe[0] - learning_rate* error * y_hat * (1.0- y_hat)
for i in range(len(row)-1):
coe[i+1] = coe[i+1] - learning_rate* error * y_hat * (1- y_hat) *row[i]
print('This is epoch < %s >, sum_error is <%.4f>' %(epoch,sum_error))
return coe
#9.逻辑回归函数,用于对测试数据预测
def logistic_regression(traning_dataset,testing_dataset,learning_rate,n_epochs):
predictions=[]
coe=estimate_coe(traning_dataset,learning_rate,n_epochs)
for row in testing_dataset:
y_hat = round(prediction(row,coe))
predictions.append(y_hat)
return predictions
seed(999)
file='./download_datas/diabetes.csv'
dataset=csv_loader(file)
str_to_float_converter(dataset)
dataset=dataset[1:]
normalization(dataset)
algo=logistic_regression
n_folds=5
learning_rate=0.1
n_epochs=1000
scores=model_test(dataset,algo,n_folds,learning_rate,n_epochs)
print('The scores of my model are : %s ' %(scores))
print('The average of scores is %.3f%%' %(sum(scores)/len(scores)))