K_means算法
数据来源:
链接:https://pan.baidu.com/s/1GT2HGMRtYJsVm7iWMi4qRw
提取码:up6x
主程序:
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
mat = loadmat("./data/ex7data2.mat")
X = mat['X']
def plot_data(X):
plt.figure(figsize=(8, 5))
plt.scatter(X[:, 0], X[:, 1], label='point')
plt.xlabel("X1")
plt.ylabel("X2")
plt.legend()
plt.title("X")
plt.grid(True)
plot_data(X)
plt.show()
m, n = X.shape
k =3 # 设置聚类中心个数
max_iters = 10 # 设置迭代次数
def init_centroids(X, k): # 随机初始化聚类中心
rand_idx = np.random.permutation(X) # 随机排列
centroids = rand_idx[:k, :] # 选前K个
return centroids
def find_closest_centroids(X, centroids): # 簇分配
idx = np.zeros(m)
for i in range(m):
min_dist = 1000 # 初始距离
for j in range(k):
dist = np.sum((X[i, :] - centroids[j, :])**2)
if dist < min_dist:
min_dist = dist
idx[i] = j
return idx
def compute_centroids(X, idx, k): # 计算各簇均值
centroids = np.zeros((k, n))
for i in range(k):
indices = np.where(idx == i)
centroids[i, :] = (np.sum(X[indices, :], axis=1)/len(indices[0])).ravel()
return centroids
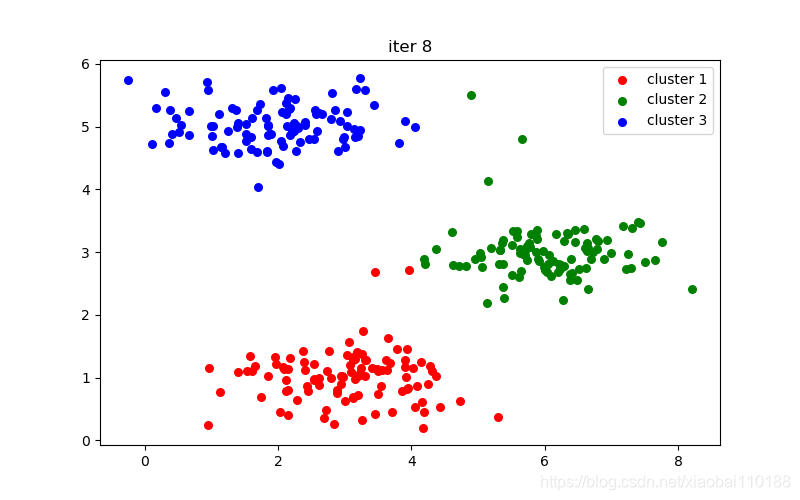
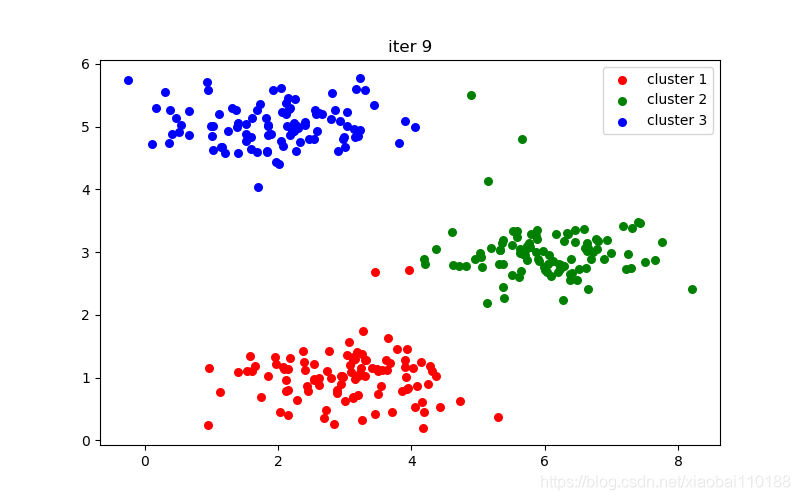
def run_kmeans(X, centroids, max_iters):
centroids = init_centroids(X,k)
for i in range(max_iters):
idx = find_closest_centroids(X, centroids) # 簇分配
centroids = compute_centroids(X, idx, k) # 移动聚类中心
cluster1 = X[np.where(idx == 0)[0], :]
cluster2 = X[np.where(idx == 1)[0], :]
cluster3 = X[np.where(idx == 2)[0], :]
plt.figure(figsize=(8, 5))
plt.scatter(cluster1[:, 0], cluster1[:, 1], s=30, color="r", label="cluster 1")
plt.scatter(cluster2[:, 0], cluster2[:, 1], s=30, color="g", label="cluster 2")
plt.scatter(cluster3[:, 0], cluster3[:, 1], s=30, color="b", label="cluster 3")
plt.legend()
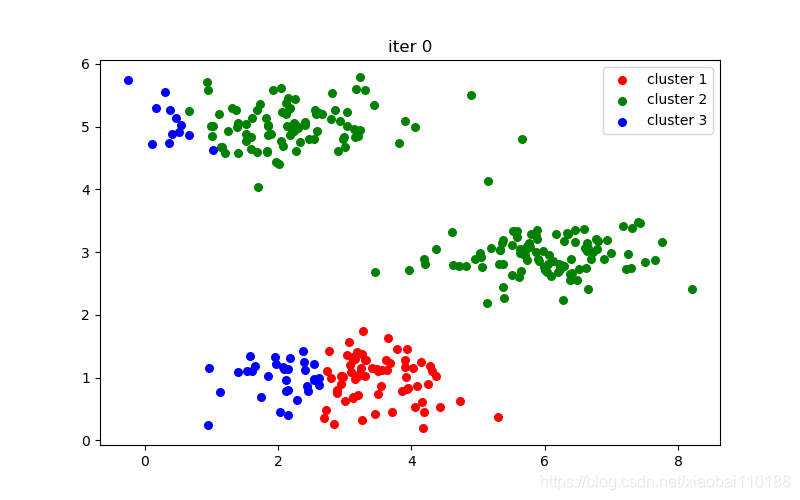
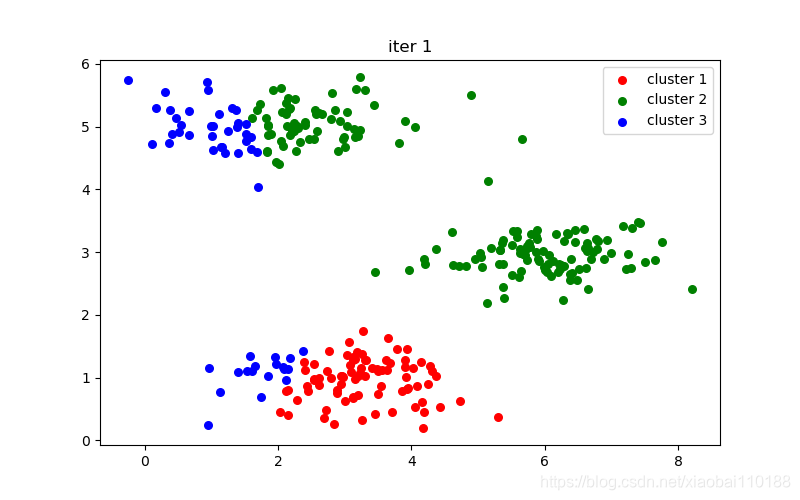
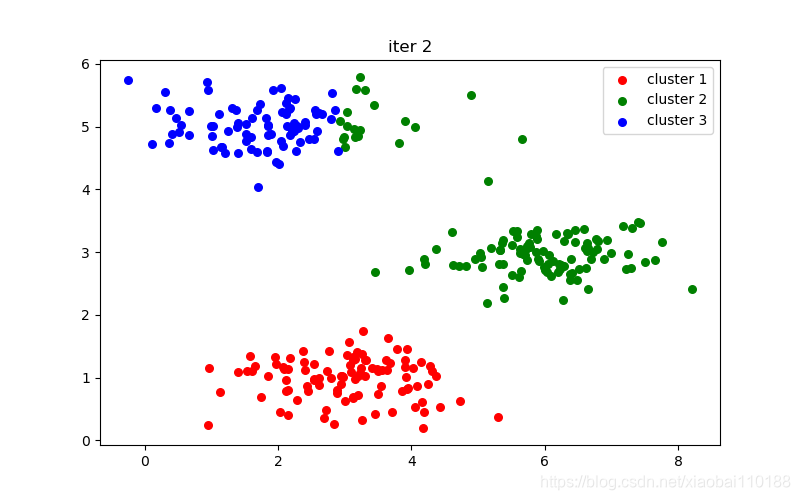
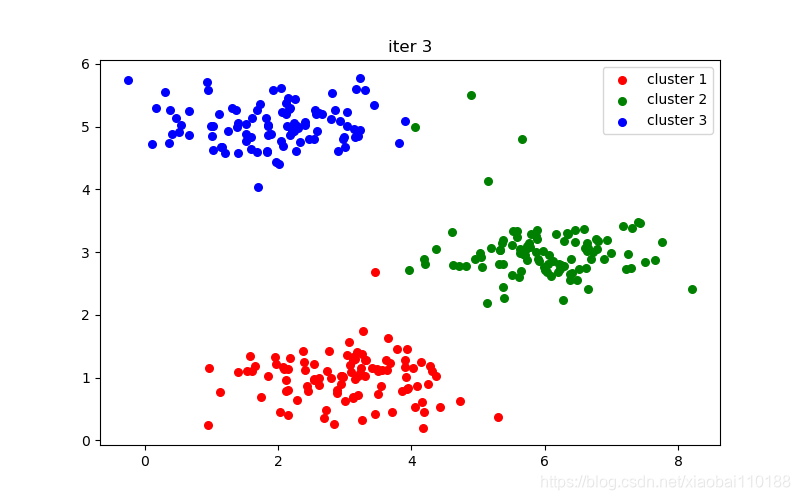
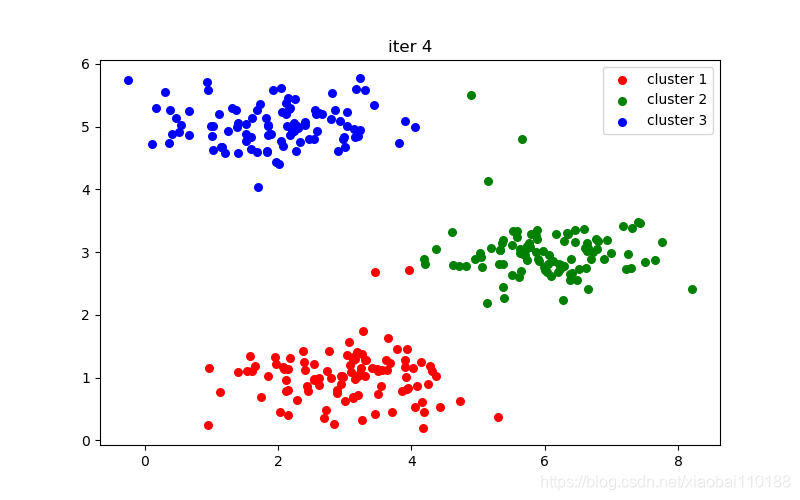
plt.title("iter %d" % i)
plt.show()
return centroids, idx
centroids = init_centroids(X, k)
run_kmeans(X, centroids, max_iters)
plt.show()
结果显示:
样本散点图: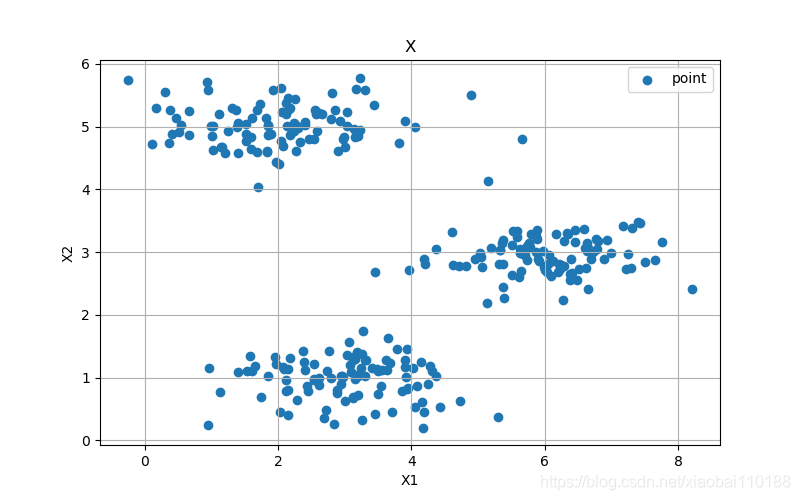
十次迭代结果图: